
The Issue
HP Vertica is an analytic platform which specialized in OLAP. It was implemented in one of our Big Data Management projects in the past and proved to be a great solution. During our development phase it has come to our attention that many people complain about the data insert speeds, especially UPDATE statements.
This article will explain how to correctly use HP Vertica Analytic Database in order to achieve great data import and update performance.
Talend Open Studio
Below I will give a brief description of the different HP Vertica components present in Talend Studio. The description table will not only describe the table but also give some valuable information as to when to use the
| Component Name | Description |
|---|---|
| tVerticaConnection | The Advanced setting – Auto Commit should not be selected as a commit will be performed after each SQL statement. Thus significantly reducing the performance of INSERT and UPDATE statements. |
| tVerticaOutputBulk | Normally used together with tVerticaBulkExec (which is described below), but can be substituted with tVerticaOutputBulkExec component. The advantage of using two components over one is that the data can be transformed before it is loaded in to the database. Additionally, an “if” trigger can be implemented. Important: The Advanced settings make it possible to change the “Row Separator” and “Field Separator”, but bear in mind that no additional CSV options such as: “Escape char” and “Text enclosure” can be selected, so make sure that the “Field Separator” you are using is not present in the data that is being loaded in to tVerticaOutputBulk component. |
| tVerticaBulkExec | Should be used together tVerticaOutputBulk component which is described below. The “Write to ROS(Read Optimized Store)” option (located in Advanced settings) is active by default, but should only be active if the Output file is greater than 100MB. So perhaps an “if” trigger should be implemented that looks at the files size from tFileProperties component. Important: When using together with tVerticaOutoupBulk make sure that the “Field Separator” value located in the Advanced settings of the component is identical to the “Field Separator” value in tVerticaOutputBulk. By default they do not match. |
| tVerticaOutput | Should be used for small Inserts or Updates. The “Commit every 100” default option set in the Advanced settings should give you an idea as to how small the Inserts and Updates should be. |
| tVerticaOutputBulkExec | Combines both tVerticaOutputBulk and tVerticaBulkExec in to a single component. Should be used if no additional data manipulation is required. The “Write to ROS(Read Optimized Store)” option (located in Advanced settings) is active by default, but should only be active if the Output file is greater than 100MB. |
| tVerticaCommit | Can be used if Auto commit is not active. |
Examples
Below you will find two jobs that showcase how impactful is the use of correct components.
Incorrect way
The first example showcases an INSERT and an UPDATE using tVerticaOutput component.
The data for the job is created using a tRowGenerator. 10 million rows of dummy data is generated, producing 700MB file. This file is then imported into a tMap and a lookup is made against randomly generated ID’s with the same sequence. There are 5 million IDs generated in the lookup which match the main input file. All that do not match are used in the Rejects output and are treated as an Update.
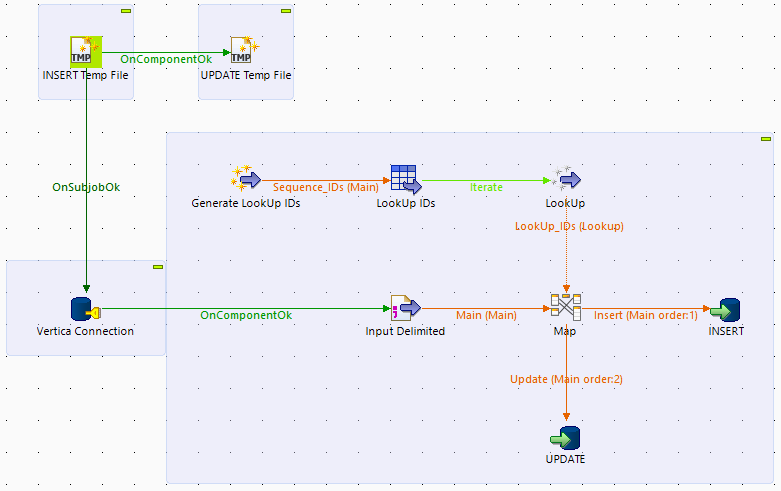
The first run is executed using the tVerticaOutput without “Use batch mode” in the advanced section of the component.
Below you will see the results:
Starting job Simple_HP_vertica at 10:10 05/02/2015.
[statistics] connecting to socket on port 3817
[statistics] connected
Job Simple_HP_vertica ended at 10:40 05/02/2015. [exit code=0]
The job was killed after 30 minutes. It has not reach the UPDATE part of the job and only finished half of the INSERTS.
The job was then run again, but this time a “Use batch mode” was activated and it was set to 10000.
Starting job Simple_HP_vertica at 10:53 05/02/2015.
[statistics] connecting to socket on port 3392
[statistics] connected
Job Simple_HP_vertica ended at 11:11 05/02/2015. [exit code=0]
After 20 minutes the job finished the INSERTS but managed only to UPDATE 10000 rows. Better but not perfect.
Correct way
Now lets make a small change to the job and replace the tVerticaOutput component with two components – tVerticaOutputBulk and tVerticaBulkExec.
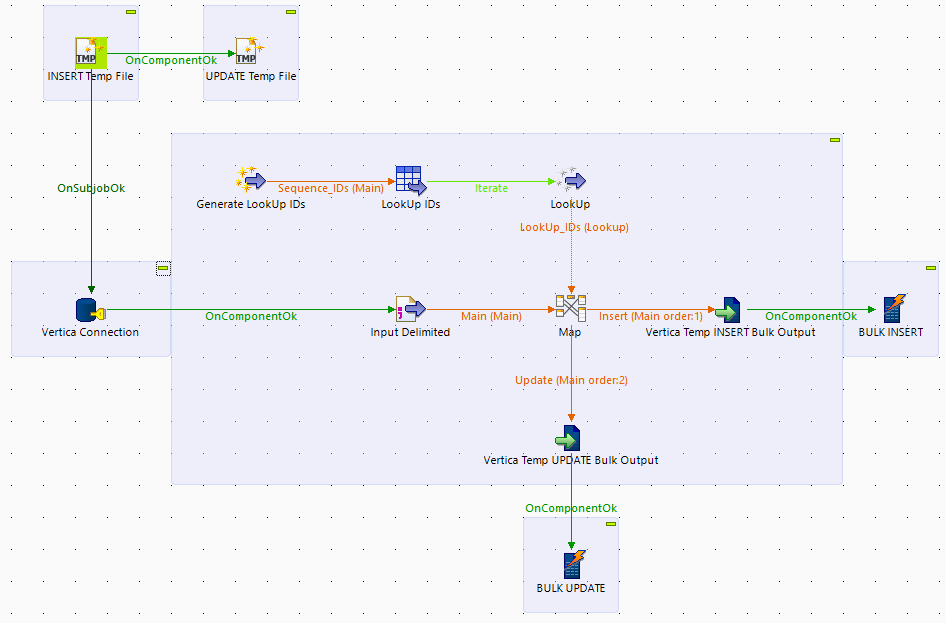
Correct update
With this change implemented the job finished in 72 seconds.
Starting job HP_Vertica at 11:12 05/02/2015.
[statistics] connecting to socket on port 3870
[statistics] connected
Input File Processed.
Commencing UPSERT
Number of records inserted into table blogPost_Test.DummyTestTable by tVerticaBulkExec_1: 5000000
Number of records inserted into table blogPost_Test.tmp_tVerticaBulkExec_3bMY2XU1 by tVerticaBulkExec_3: 5000000
72seconds Job Execution Time 72661 milliseconds
[statistics] disconnected
Job HP_Vertica ended at 11:13 05/02/2015. [exit code=0]
Conclusion
As you can see depending on what type of components are used in the job, the overall performance may change drastically. Make sure that you use the correct components and settings for those components to achieve the best results.
Instead of going on forums and proclaiming that the database is slow or that a Talend component is not working properly.
Hi , I have a question, I do not see any column used in bulk update component. how the bulk update will be performed?